How to Setup Ollama locally on Windows
Running large language models (LLM’s) and managing them is a pain because of its complexity. In this article we will discuss about how to setup Ollama locally on your windows system with very minimal steps. And once we are done with the setup we will use some of the open source models like Mistral/ blah / blah on a windows machine.
Downloading Ollama on your windows Machine

You can downloading Ollama from official website: www.ollama.com. Apart from windows machine, ollama is readibly available for macOS, Linux as well.
Ollama Architecture (Key Components)
Ollama operates on a client-server architecture. The server exposes multiple APIs that handle core functionalities such as model registry access, generating predictions based on prompts, and managing user interactions. The client can be anything from a command-line interface (CLI) to a web-based platform, offering flexibility depending on users’ preference. Ollama’s architecture includes specific APIs for tasks like loading models, generating text based on user prompts, and interacting through conversation. Examples include:
- Generate API: Allows users to generate text completions based on specific prompts
- Chat API: Facilitates ongoing conversations, maintaining context to ensure relevant responses.
Ollama System Requirements:
To run Ollama efficiently, your system should meet the following requirements. These requirements ensure that Ollama runs smoothly and efficiently, allowing you to leverage large language models effectively on your local hardware.
Operating System For Ollama Setup
- Linux: Ubuntu 18.04 or later
- macOS: macOS 11 Big Sur or later
- Windows: Support is available through WSL2
Processor
- Minimum: Quad-core CPU
- Recommended: 8 cores for larger models (e.g., 13B parameters)
- Optimal: Intel’s latest processors or Zen4-based AMD CPUs with AVX512 support
Memory (RAM) Required for Ollama Models
- Minimum: 8GB for smaller models (e.g., 3B parameters)
- Recommended: 16GB for medium-sized models (e.g., 7B parameters)
- Optimal: 32GB or more for larger models (e.g., 13B parameters)
Disk Space
- Minimum: 12GB for installing base models
- Recommended: 50GB to accommodate additional model data and datasets
GPU (Optional but Recommended)
- Recommended: NVIDIA GPUs with a compute capability of at least 5.0
- VRAM: 8GB for medium-sized models (e.g., 7B parameters)
Internet Connection
- A stable internet connection is recommended for downloading models and updates
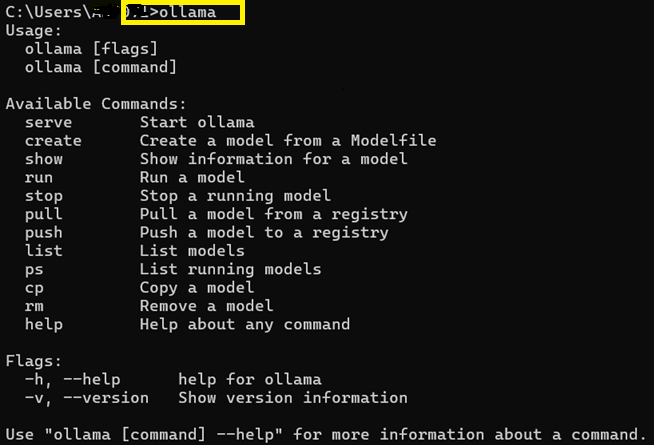
On windows machine Ollama gets installed without any notification, so just to be sure to try out below commands to be assured Ollama installation was successful.
-> Type ollama in Command Prompt (CMD)
lets try to experiment and run our first model on LLM. I will go ahead with mistral 7B model, if you are running it for the first time, this might take some time to download.

You can ask your questions directly on the terminal or you can use the API directly to connect with the ollama client, below i have shared the sample code for ollama client.
import ollama
# Initialize the Ollama client
client = ollama.Client()
# Define the model and the input prompt
model = "llama2" # Replace with your model name
prompt = "What is Python?"
# Send the query to the model
response = client.generate(model=model, prompt=prompt)
# Print the response from the model
print("Response from Ollama:")
print(response.response)