In the era of large language models (LLMs), processing vast amounts of textual data is common practice. While raw text alone can suffice for advanced LLM applications, it lacks crucial nuances and linguistic information. Using Docling transform any document into structured data from unstructured documents. Docling supports multiple formats including PDF, DOCX, XLSX, HTML, images, and more. It has a capability to extract page layout, reading order, table structure, code, formulas, image classification, and more.
Docling, a Python library for document linguistics, serves as a critical pre-processing tool, enabling LLMs to move beyond simple text ingestion towards a deeper, more contextually aware understanding of documents.
Why Use Docling?
Docling revolutionizes document processing by effortlessly parsing diverse formats, including advanced PDF understanding. It seamlessly integrates with the generative AI ecosystem, significantly improving efficiency and accuracy in handling complex documents.
- Ease of Use: DocLing is designed to be user-friendly, making it easy to integrate into your projects.
- Versatility: It supports various linguistic annotations such as part-of-speech tags, syntactic structures, and semantic roles.
- Efficiency: DocLing is optimized for performance, allowing you to process large volumes of text data quickly and efficiently.
Getting Started with Docling
Installation
To install Docling, you can use pip:
pip install doclingBasic command to start with document extraction in structured manner:
import docling
from docling.document_converter import DocumentConverter
path = "C:\Users\docling_240809869.pdf"
converter = DocumentConverter()
result = converter.convert(path )
print(result.document.export_to_markdown())
print(result.document.export_to_text())
print(result.document.export_to_html())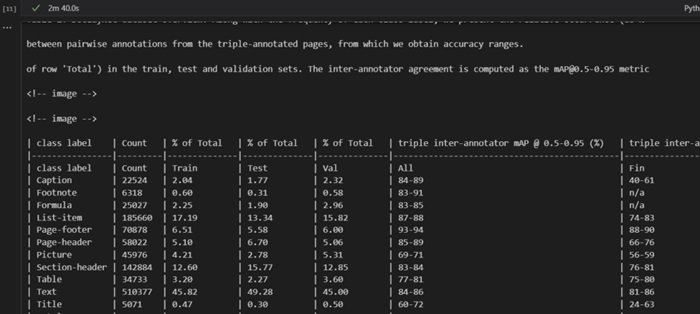
in the above picture you can see the extraction of tables from the pdf documents. Likewise docling is capable of extracting tables, images, figures, formulas etc from any document source file.
Docling Architecture:
With Docling Document brings together several essential features common to documents, enhancing their structure and usability. A Unified Document Representation Format to extract various content types, including text, tables, and images.
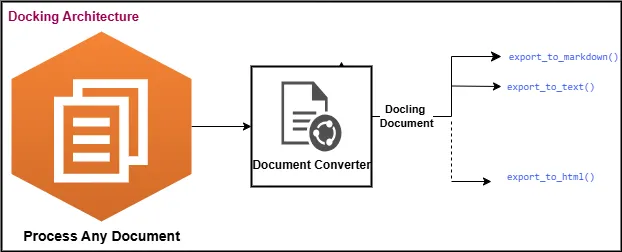
How Docling Works: Understading docling documents
A Docling Document is designed to organize document content into two main categories: Content Items & Content Structure, ensuring an efficient approach for handling various types of information.
Content Items: The first category includes various content items, each stored in specific fields:
- Texts: This field contains all text representations of the documents, such as paragraphs, section headings, and equations.
- Tables: All table data is stored here, represented by the TableItem type, which can include structure annotations.
- Pictures: This field stores all images, categorized under the PictureItem type and can also carry structure annotations.
- Key-Value Items: This field contains all key-value pairs.
Content Structure: The second category focuses on the content structure, encapsulated in following fields:
- Body: This is the root node of a tree structure representing the main document body.
- Furniture: This field includes items that are not part of the main body, such as headers and footers.
- Groups: This field contains items that act as containers for other content items, such as lists or chapters
Docling also supports Integration with LangChain, LlamaIndex, Crew AI, and Haystack for enhanced AI capabilities. In the future tutorials I will be sharing advanced version of docling code where you will be able to extract images, tables and other formats. Stay Tuned!

